Improving Automated Testing, Interoperability, and Privacy of OpenSRP
Through a committed collective of technology, research, and implementation partners, OpenSRP has matured into a fully-fledged digital health platform with multiple national deployments, high performing technology at scale, and emerging documentation around use cases for RMNCH, TB, HIV, malaria and early childhood development.
With PATH’s support, we recently added robust testing, expanded interoperability support, and increased security and privacy features to enhance the shelf-readiness of OpenSRP. The outputs of this work means we can more easily deploy OpenSRP and offer better support in our current and future deployments, with the goals of broader adoption and interoperability aligned with the OpenHIE architecture.
This blog post provides technical context, describes what we did (automated testing using Gherkin syntax for BDD), and examines our team’s lessons learnt.
The Core Architecture
OpenSRP has three core technical components: (1) native Android client, (2) Java server, and (3) data warehouse. Our work focused on automating the unit, functional, and integration tests in the Android client and Java server, improving the REST Application Programming Interfaces (API) in the Java server, and improving the Extract, Transform, Load (ETL) process that moves data from the OpenSRP server to the data warehouse in order to protect personally identifiable information.
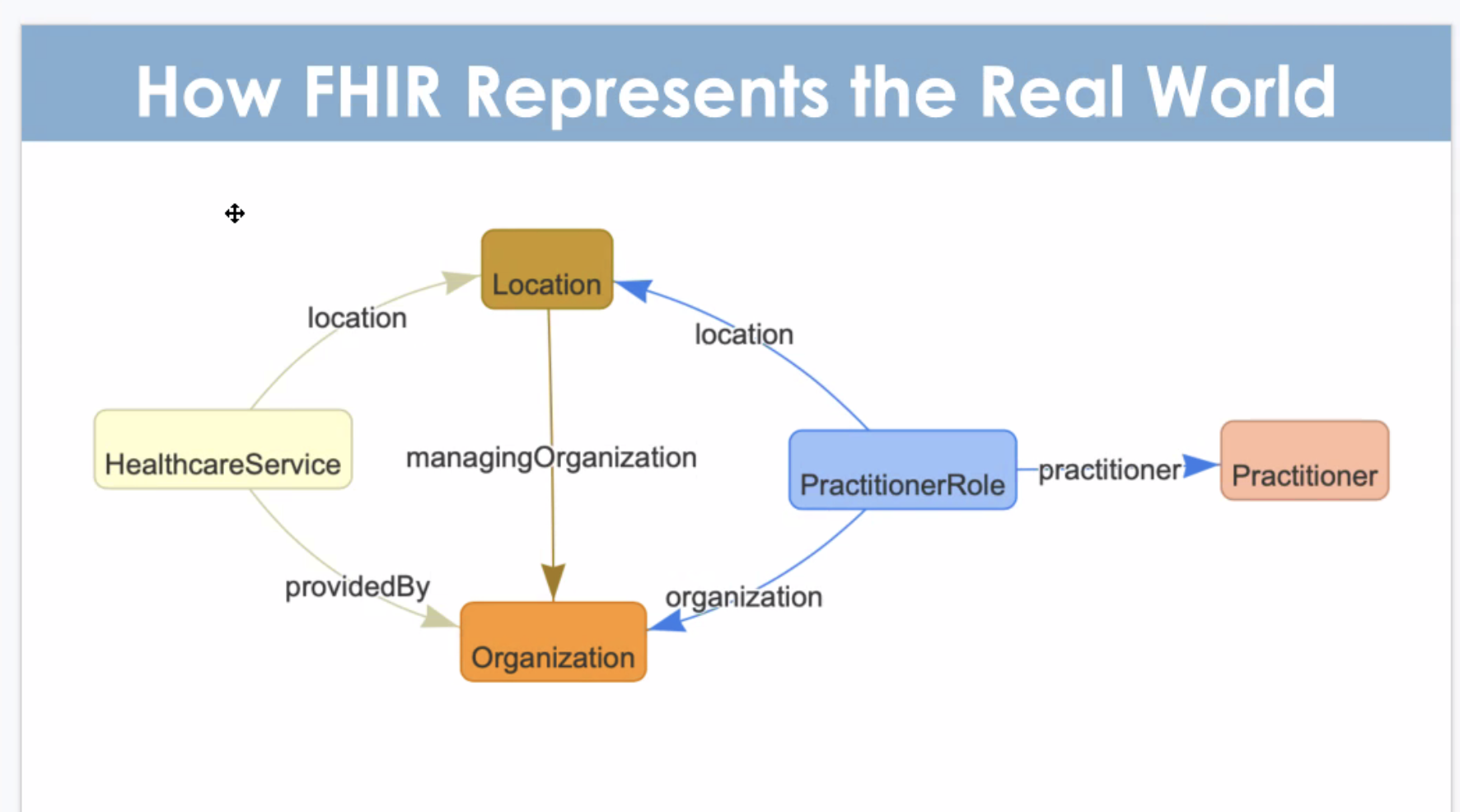
The Android client, dubbed FHIR Core, is a Kotlin application for delivering offline-capable, mobile-first healthcare project implementations from local community to national and international scale using FHIR and the WHO Smart Guidelines on Android. FHIR Core is architected as a FHIR native digital health platform powered by Google’s Android FHIR SDK and HAPI FHIR. FHIR Core’s user experience and module oriented design are based on over a decade of real-world experience implementing digital health projects with OpenSRP. Additionally, the FHIR Core APIs are mCSD (mobile Care Services Discovery) compliant and capable of masking personally identifiable information.
Why an mCSD compliant profile?
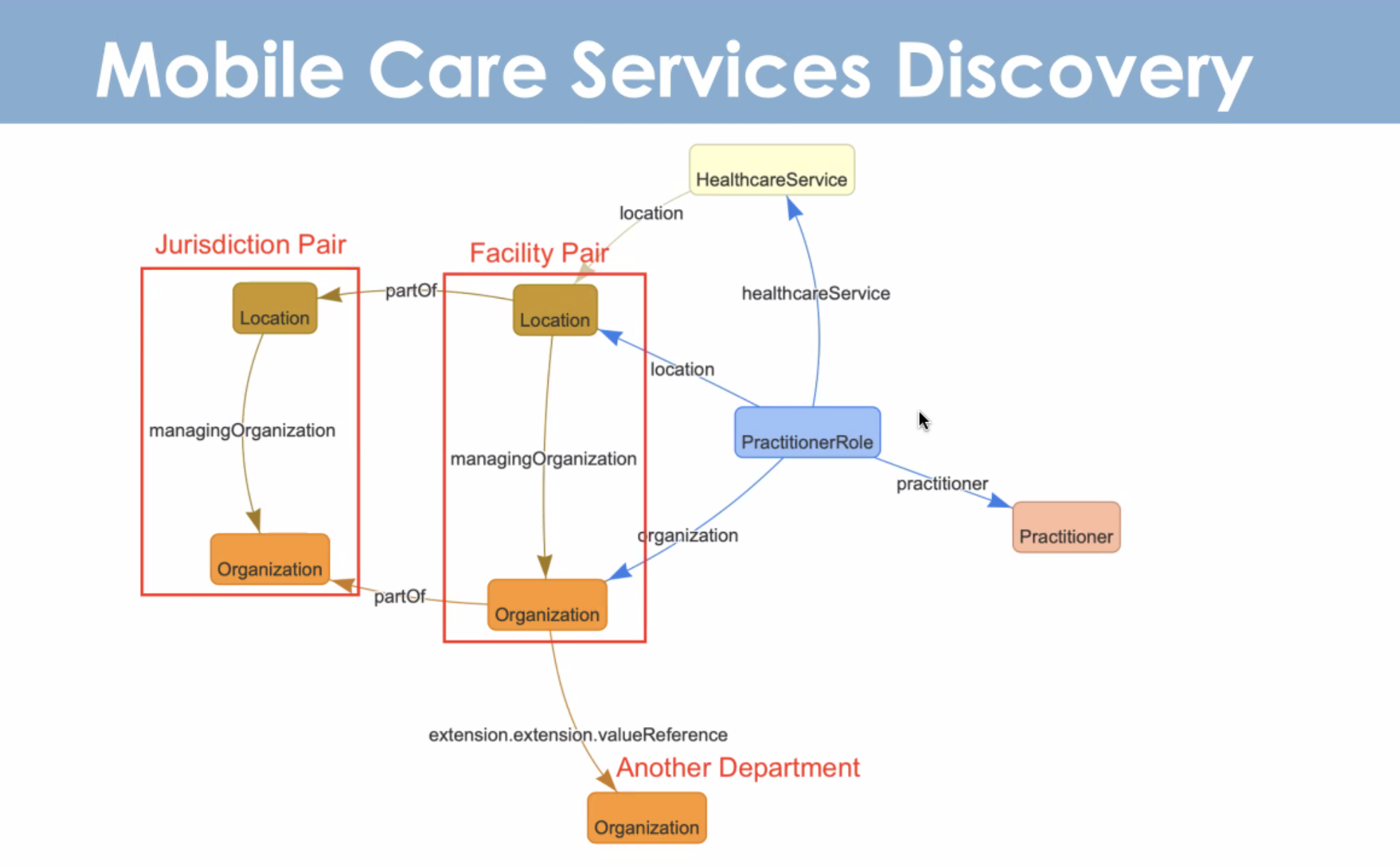
The Care Services Discovery (CSD) profile supports queries across related directories containing data about organizations, facilities, services and providers. The CSD profile can respond to queries such as:
- Which facilities are associated with which organizations?
- What services are provided at specific facilities or, conversely, where are the facilities that provide a specified service?
- Who are the providers associated with a particular organization; what services do they provide; at which facilities do they provide these services, and when?
- Within a specified date range, when are the schedulable time slots for the provider of a specific service?
The Mobile mCSD Profile supports RESTful queries across related care services resources, such as Organizations, Locations and Practitioners. (If you are curious, you can learn more in the IHE ITI Technical Framework Supplement – Mobile Care Services Discovery PDF.)
How FHIR represents the Real World
Mobile Care Services Discovery
Why Behavior-Driven Development (BDD)?
BDD grew out of Test-Driven Development (TDD) and Acceptance Test-Driven Development (ATDD). It is a part of Agile software development processes that encourage collaboration between developers, QAs and non-technical business participants in a software project. BDD focuses on identifying the desired behavior of a given feature from the start. In this context, behavior means how a product or feature operates and is defined as a scenario consisting of inputs, actions and outcomes.
We settled on using BDD based on the following goals:
- Ensure that the requirements can be understood by the entire team and project stakeholders.
- Prevent possible issues, rather than put out fires that are found later.
The collaborative BDD approach brings the business and the technical aspects of projects together. This allows teams to better communicate requirements, detect problems early on, and more easily maintain software over time. To implement BDD with OpenSRP we deployed an automated test framework via Cucumber using the Gherkin language.
What is Cucumber?
Cucumber is an open-source software testing tool built to support BBD. Cucumber reads tests written in Gherkin, runs the application as described by the test case, and validates that the application functionality aligns with the expectations described by the tests. It does this by working through Gherkin scenarios, which are written as a sequence of steps. Cucumber will then create a report showing whether each step and the scenario as a whole were successful. Cucumber was originally written for Ruby but it now supports dozens of languages and provides scripts for test automation.
What is Gherkin?
Gherkin is a language that defines test steps and scenarios to be executed through Cucumber. The language uses plain English so that it can describe the use cases for a software system in a way that can be read and understood by almost anyone. This syntax promotes the behavior-driven methodology of testing because it allows developers, managers, business analysts and other parties involved to understand the requirements of the project and its life cycle. The language makes it easy to create simple documentation of the code that’s being written.

Gherkin syntax structure
Below is a sample test authored using Gherkin syntax to test the creation and editing of a Patient record.
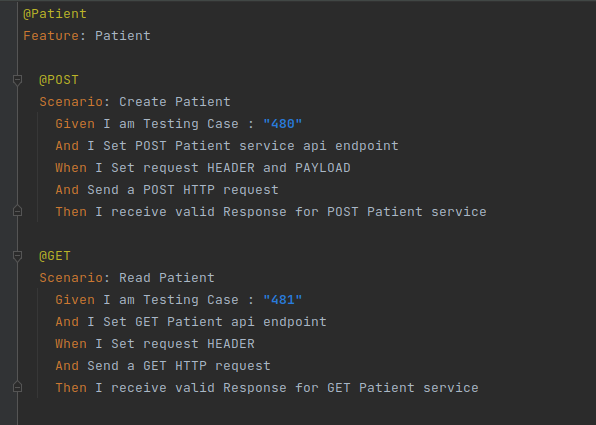
How we went about testing
After careful analysis and selection of the tools, we embarked on first documenting the testing objectives and scope for both functional and non-functional tests. For the functional test, our goal is that
- Unit tests – should have a 100% pass rate and code coverage of not less than 80%
- Integration testing – will be use Cucumber and should have a coverage of not less than 70%.
For the non-functional tests we described metrics and thresholds for Performance and Load testing.
We used an Agile Methodology for the testing, applying an incremental testing approach where every release is tested thoroughly to ensure that any errors in the system are fixed before the next release. This was done by progressing through the 4 levels listed below:
- Unit Testing: Done by the engineers when building the application.
- Integration Testing: Individual software modules are combined and tested as a group, this includes the Cucumber tests
- System Testing: Conducted on a complete, integrated system to evaluate the system’s compliance with its specified requirements.
- API testing: Test all the APIs created for the software under test. This includes unit tests to be done by engineers and integration tests written by the QA team.
We then documented all reported issues, including errors and improvements/feature requests, with errors prioritized. With this we defined the criteria to guide us towards test completeness:
- 80% test coverage on Unit tests
- 70% test coverage on BDD integration tests
- All Manual & Automated Test cases executed
- All open errors are fixed or will be fixed in the next release
Lessons learnt
The following key highlights described the gains achieved on OpenSPR FHIR Core as a result of this work.
- Automated testing saves us resourcing: time and money
Manually repeating these tests is costly and time-consuming. Once created, automated tests can be run repeatedly at no additional cost and they are much faster than manual tests. Automated software testing reduces the time we need to run tests from days to hours. This time saving translates directly into cost savings.
- Vastly increases our test coverage
Automated software testing increased the depth and scope of tests to help improve software quality. Lengthy tests that are often avoided during manual testing can be run unattended. Automated software testing can look inside an application to examine memory contents, data tables, file contents, and internal program states to determine if the product is behaving as expected. Test automation can easily execute thousands of different complex test cases during every test run providing coverage that is impossible with manual tests.
- Testing improves accuracy
Even the most conscientious tester will make mistakes during monotonous manual testing. Automated tests perform the same steps precisely every time they are executed and never forget to record detailed results. The QA team was freed from repetitive manual tests to have more time to create new automated software tests and deal with complex features.
- Automation does what manual testing cannot
Even the largest software and QA departments cannot perform a controlled web application test with thousands of users. Automated testing allowed us to simulate tens, hundreds or thousands of users interacting with a web and mobile application
- Automated testing helps developers and testers
Shared automated tests can be used by developers to catch problems quickly before sending them to QA. Tests can run automatically whenever source code changes are checked in and notify the team or the developer if they fail. Features like these save our developers time and increase their confidence.
- Allow a focus on challenging non-automatable tasks
Executing repetitive tasks with automated software testing gives your team time to spend on more challenging and rewarding projects. Team members improve their skill sets and confidence and, in turn, pass those gains on to their organization.
OpenSRP is a person-centered digital register and point-of-care software system for frontline workers that offers a suite of customizable features for countries wanting to digitize their legacy paper registers, which complements and integrates with common national-level digital healthcare systems (HMIS, EMR, LMIS). In 2018, OpenSRP was recognized as a global good and has progressively improved in maturity through the support of consortium members, implementing partners, and donors. We offer OpenSRP Enterprise solutions to organizations, governments, and health systems around the world.