Redirecting HTTP traffic while using AWS Target Groups
A few months ago we received a support query from a user who was unable to log in. We couldn’t replicate the issue and they weren’t able to work with us to get it fixed. We concluded that they were doing something unique and had ended up fixing it from their end somehow.
Fast forward to March 5th, when we sent email invitations for a Nairobi Linux Users Group meet-up with an HTTP—not HTTPS—link to the login page, http://ona.io/login, and got a complaint that the site did not redirect to HTTPS on the /login or /join routes. This was a serious problem because we only perform sign-ups, log-ins or any other form of data exchange over HTTPS, including setting cookies.
When we find the user’s authentication cookies are not set, or are expired, we reload the page so that they can get a new authentication cookie. We implemented this as shown below, by checking for a 401 status from the OnaData API. More of that code is here.
(defn http-request
"Wraps cljs-http.client/request and redirects if status is 401"
[request-fn & args]
(let [response-channel (chan)]
(go
(let [original-response-channel (apply request-fn args)
{:keys [status] :as response} (<! original-response-channel)]
(if (= status 401)
(set! js/window.location (.href js/window.location))
(put! response-channel response))))
response-channel))As a consequence of this setup, when a user connects over HTTP and is not redirected to HTTPS they can end up in an endless loop of reloads when they try to sign-up, log-in or submit data in any other way. When we tried it ourselves, HTTP redirected to HTTPS just fine. However, we noticed that it didn’t redirect on a fresh Firefox install, assuming this fresh install didn’t have add-ons like HTTPS Everywhere.
Narrowing down the problem
Now that we had verified there was a problem, we had to figure out why it didn’t happen anywhere else, why we hadn’t noticed it before, and why it only happened on fresh Firefox installs.
Enter HSTS
From Wikipedia: “HTTP Strict Transport Security (HSTS) is a web security policy mechanism which helps to protect websites against protocol downgrade attacks and cookie hijacking.”
We already included the HSTS header in our responses. If you use an HSTS-enabled website over HTTPS your browser saves the HSTS header and uses HTTPS in future requests.
With our broken setup, if you visited the root site itself over HTTP, http://ona.io, it properly redirected to HTTPS. Your browser would take note of the HSTS header, save it, and redirect to HTTPS for other ona.io routes, e.g. http://ona.io/login and http://ona.io/join would be redirect to https://ona.io/login and https://ona.io/join, respectively. However, if you had never visited Ona, and your first visit was to a non-root HTTP URL, e.g. http://ona.io/login, the HSTS header would not be set, your cookie would not be set and you’d end up in a redirect loop. This is why we only saw the problem with fresh browser installs and non-root HTTP URLs.
Digging deeper
Next, we noticed that the domain names that weren’t using AWS Target Groups redirected to HTTPS just fine and those that did use AWS Target Groups were not redirecting. With AWS Target Groups being the common factor, we assumed they were the cause and looked for more evidence.
What are AWS Target Groups and why use them?
AWS Target Groups are a way to route different requests to different servers based on the load balancer they are attached to and the requested path. For the new AWS Elastic Load Balancers, Target Groups are the standard (and only) way to connect servers to a route. In our setup, they let us send traffic to either the API servers or the UI servers depending on what path you request for the same domain. Target Groups have their own health checks, similar to the health checks on Classic AWS Elastic Load Balancers, and if a Target Group fails its health checks Elastic Load Balancer traffic will not be routed to it. Refer to the AWS Target Groups documentation for more on this.
HTTPS traffic
As you can see below, we had no problem handling HTTPS traffic with our setup. We responded with a 200 OK as intended.
$ curl --head -X GET "https://ona.io/login"
HTTP/1.1 200 OK
Set-Cookie: AWSALB=PqCh/O; Expires=Thu, 23 Mar 2017 06:18:24 GMT; Path=/
Strict-Transport-Security: max-age=31536000; includeSubDomains;Note: The AWS load balancer cookie is used by the load balancer to route a user’s requests to the same application server they used in the previous request.
HTTP traffic
The HTTP response showed that we did not redirect traffic to HTTPS and it also included the HSTS header, even though the HSTS header is only in the HTTPS section of the server configuration. Somehow the application server was responding to HTTP traffic using HTTPS instructions.
$ curl --head -X GET "http://ona.io/login"
HTTP/1.1 200 OK
Set-Cookie: AWSALB=ZplUR; Expires=Thu, 23 Mar 2017 06:20:07 GMT; Path=/
Strict-Transport-Security: max-age=31536000; includeSubDomains;What we knew and what we wanted
Looking at our Target Groups, we didn’t have a Target Group for port 80 (HTTP), but we did have a Target Group for port 443 (HTTPS). We knew that the load balancer, with Target Groups configured for port 443, was working well. We also knew that HTTP requests via the domain name were going through the load balancer to the reverse proxy (we use NGINX), but we didn’t know why those from the load balancer to the reverse proxy were failing.
From the response to the HTTP request above, we could tell that the load balancer was routing port 80 requests to the same Target Group used for port 443, then to the reverse proxy for it to decide what do with the request. Moreover, from looking at the reverse proxy logs, we saw that HTTP requests ended up in the HTTPS logs.
Solution: just add a rule for port 80. Wrong!
We knew that the load balancer makes health check requests to the application servers using the IP address and not the domain name, which seems to be reasonable, yet we were blocking IP address requests as shown below.
server {
listen 80 default_server;
server_name _;
return 444;
deny all;
}We block IP address requests in order to avoid crawlers or malicious actors that target a range of IP addresses, and through this end up placing unnecessary load on our servers. We also don’t want our application server to respond to IP address requests, again to avoid unnecessary load on the application servers. For example, here’s a normal crawling request by IP address from our logs:
180.76.15.155 - - [15/Mar/2017:13:20:43 +0000] "GET / HTTP/1.1" 301 185 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"With IP address requests being blocked, just adding a Target Group for port 80 wouldn’t work. The health check requests would get denied, and the load balancer would assume the application server is unhealthy on port 80 and not route port 80 traffic at all. An arguably worse position to be in.
Note: We don’t have a rule to block or deny IP address requests to port 443 because HTTPS requests depend on domain names. This wouldn’t be the place we want to handle this because we’d end up trying to make a firewall out of Nginx.
What we want is for HTTP traffic to redirect to HTTPS as a final result. On top of this, we want to use the application server’s reverse proxy to redirect HTTP traffic to HTTPS, and not use the load balancer. For this to happen, the load balancer has to forward port 80 traffic to the reverse proxy and the reverse proxy should decide what to do with the traffic. In this case, we want the reverse proxy to respond with a 301 redirect and send the request to HTTPS.
As a start, we added a Target Group for port 80 traffic and had it expect a status code 301 permanent redirect. We then added a listener on the load balancer for the Target Group. We could now see IP address requests behaving as in the snippet below:
$ curl --head -X GET "http://35.157.7.224"
curl: (52) Empty reply from serverThis was a result of the load balancer finding the application server unhealthy on port 80 because its requests were being denied. To solve this, we had to stop denying IP address requests and instead redirect them to the corresponding domain name. So our default configuration had to change to the below, with <nginx_server_name> being the domain name we wish to expose for that server.
server {
listen 80 default_server;
server_name _;
return 301 http://<nginx_server_name>$request_uri;
}Now the health check will find the expected response and deem the server healthy.
Final and desired result
Our desired result is to redirect IP address requests to the corresponding domain name and let the configuration for the server handling that domain name handle said requests. We also make sure not to manipulate the protocol, HTTP to HTTPS, on IP address requests because they would fail if the reverse proxy doesn’t support HTTPS. This also gives the correct response to crawlers.
$ curl --head -X GET "http://52.59.26.201"
HTTP/1.1 301 Moved Permanently
Location: http://ona.io/Which you can see happening on some popular domains:
$ curl --head -X GET "http://74.125.230.163"
HTTP/1.1 301 Moved Permanently
Location: http://www.google.com/Name requests also get properly routed to HTTPS using a 301 redirect.
$ curl --head -X GET "http://ona.io/login"
HTTP/1.1 301 Moved Permanently
Location: https://ona.io/loginHandling HTTP at the reverse proxy
We also want NGINX to handle port 80 traffic using recommendations from NGINX Pitfalls and Common Mistakes under Taxing Rewrites. With this we can “effectively avoid doing any capturing or matching at all.”
server {
listen 80;
listen [::]:80;
server_name ona.io;
return 301 https://$server_name$request_uri;
}Recommendations from the HSTS Preload List Submission site
To double-check that we had fixed our problem with HSTS, we used the HSTS Preload List Submission site to validate our configuration. Before we had this result: 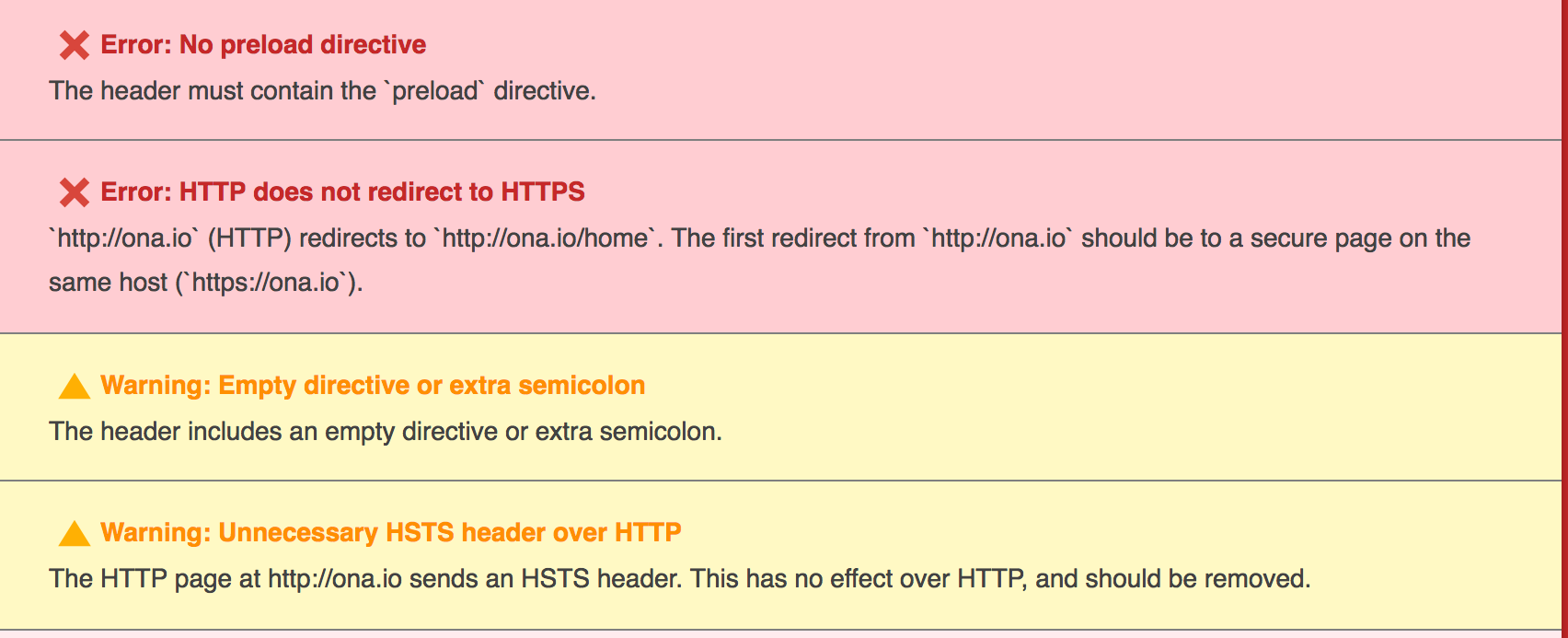
Now we have this: 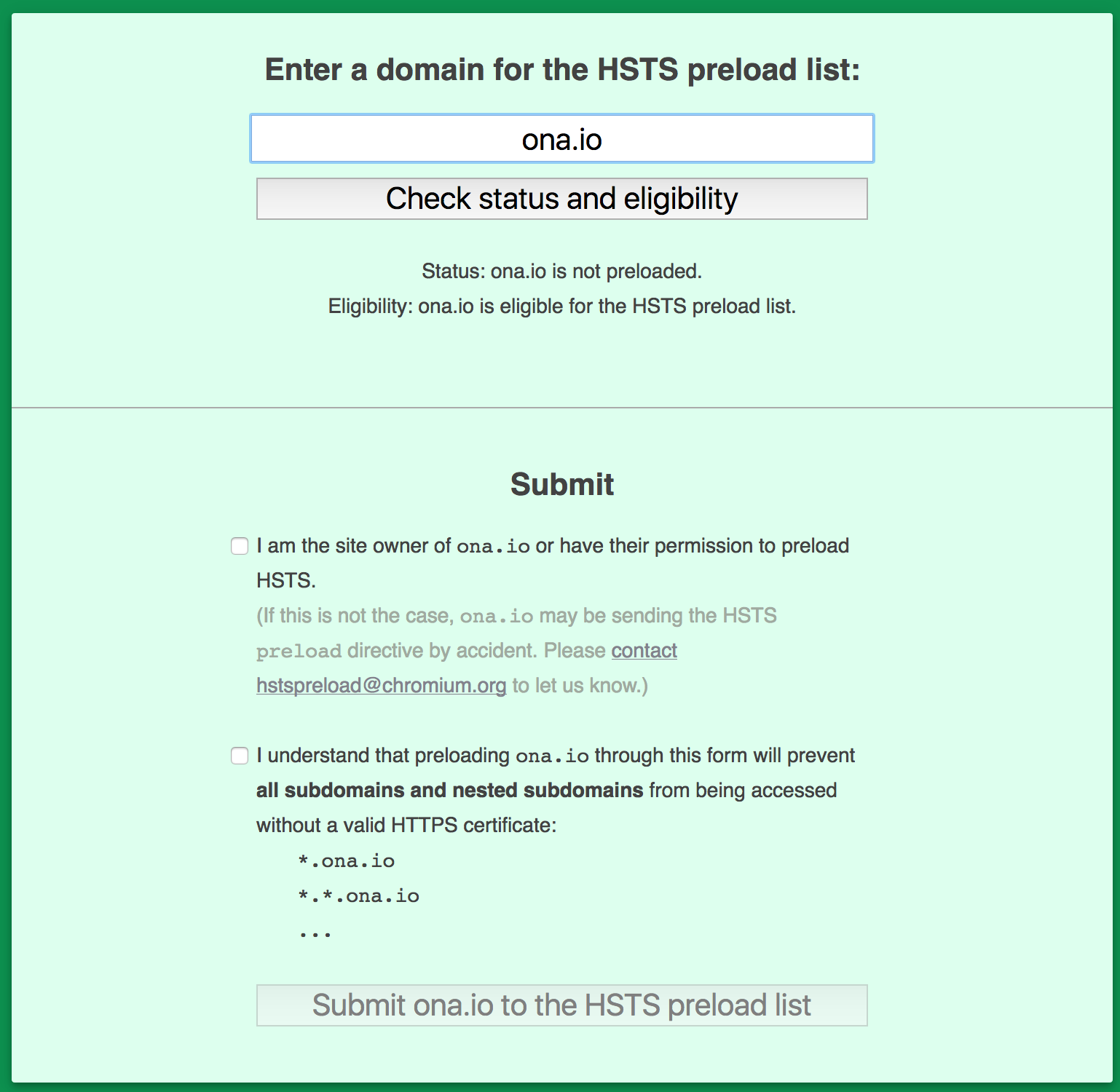
Wrapping up
We started with a broken configuration that put a small subset of HTTP requests into a redirect loop. The users behind these requests likely ended up going to our HTTPS URL and incidentally fixing the HTTP problem, then never following up with us. After digging in, we found that we had misconfigured both our AWS Elastic Load Balancer Target Groups and our reverse proxy rules. This was a problem for our users and for our HSTS configuration. By correcting these configuration problems we have removed the redirect loop and fixed our HSTS configuration.