Three Advantages of a Modern Data Stack for Digital Development

Managing data in the development sector can be messy. Development organizations want reliable data to assess the effectiveness of their interventions, aiming for continuous improvement and evidence-based decision-making. They strive to expand beyond traditional surveys and Monitoring and Evaluation (M&E) by digitizing operations and taking advantage of innovations like mobile data collection to gain better insights.
This leads to an increase in both the amount of data and diversity of sources (eg. real-time, static, database, API) organizations need to manage and draw insights from. We’ve seen first hand how organizations struggle to manage this complexity, which results in fragmented data systems instead of helpful insights. Data management becomes a burden instead of an enabler.
The data stack transition
Luckily, these data challenges are not unique to development. Best practices and analytics technologies from other sectors have emerged recently, forming the basis of the modern data stack. The improved tooling has enabled data-savvy organizations to adopt a more agile, scalable, cost-effective, and simpler approach to data management.
Software engineers use the term technology stack to describe the internal working of an application or service by referring to the various libraries and programs that comprise the solution. In the data world, a data stack is a way of articulating all the systems needed to provide the analytics solution.
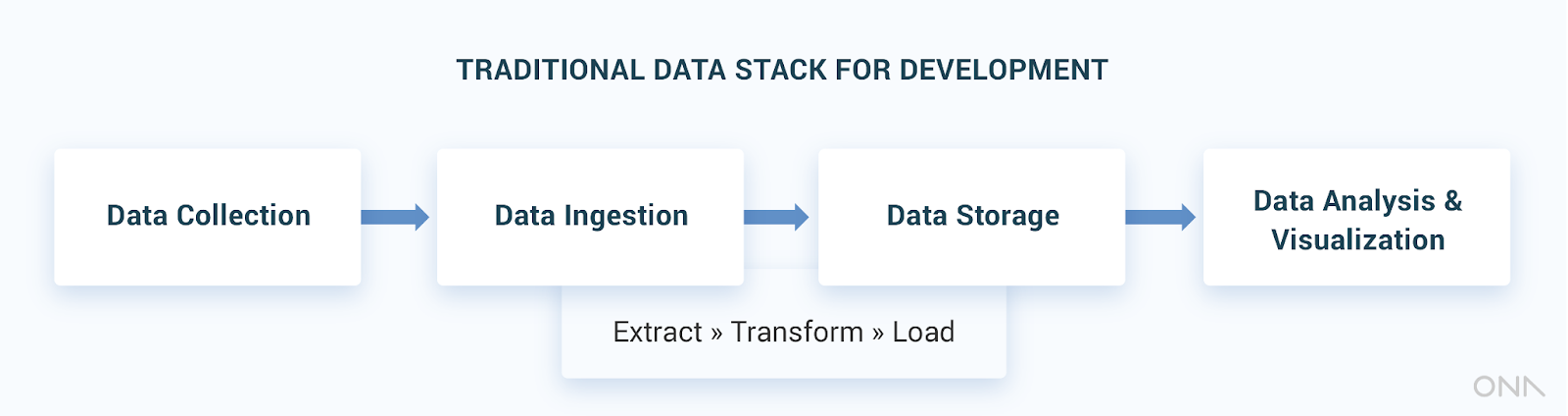
In the development sector, a traditional data stack usually consists of some of the following components, sometimes called layers.
- The first layer is data collection, referring to tools to gather static and real-time data from multiple sources, such as ODK forms, custom applications, spreadsheets, or internal / external databases.
- The second layer is data ingestion: scripts or programs transferring data from the different data sources to a centralized database (eg. data warehouse) using the Extract Transform and Load (ETL) process.
- The third layer is data storage, where data is housed in a centralized repository. Since the data format is written during the ETL process, the data is generally optimized for specific and predetermined analyses.
- The last layer refers to data analysis and visualization, reporting tools connected to the data warehouse to run reports and/or power dashboards, such as Superset, PowerBI, or even Excel spreadsheets.
Sometimes the functions for multiple layers are performed by a single application, but the logical grouping is the same.
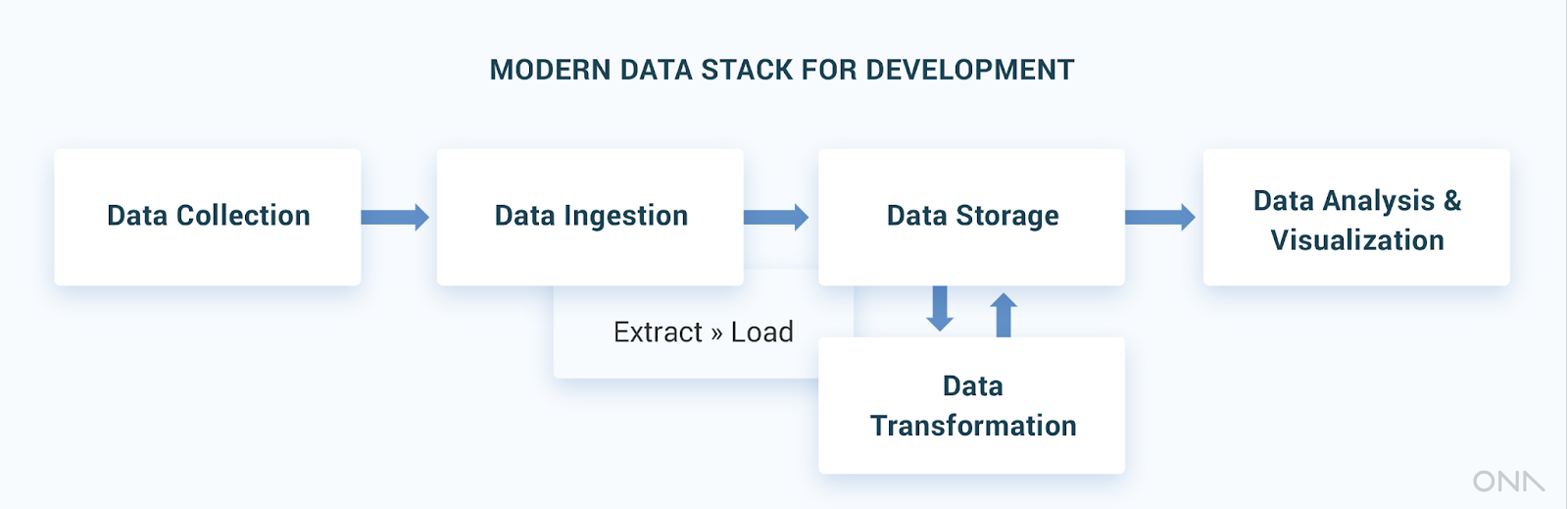
The critical change between a traditional and modern data stack is in the approach to data ingestion and storage: from ETL to ELT. The introduction of cloud based data warehouse technologies, like BigQuery, Redshift, and Snowflake, brought down the cost of running a data warehouse by orders of magnitude, while expanding speed and processing power.
As the capabilities of these databases rapidly improved, organizations began dumping raw data in their data warehouses, where it is transformed afterwards. The process of ETL (Extract Transform and Load) has become ELT (Extract Load and Transform), with dedicated tooling making this step easier than ever.
With data in a centralized place, data transformation is easier and more flexible for inquisitive analysts, especially when using dedicated tools.
One open-source software in particular, the Data Build Tool (DBT), has revolutionized the approach to data transformation. With DBT, analysts can write several scripts in the well known SQL language and create templates to relate them together. Indicators or metrics specific to the organization are defined once and can be governed like software: in a repeatable, testable and documented code repository.
The tool was born out of large organizations working on massive cloud-based data warehouses, but can be used effectively on Postgres and other conventional databases and even on premise. Data transformation is now its own layer in the stack.
Modern Data Stack Advantages
Embracing the modern data stack can have tremendous benefits for organizations in the development sector. In our work at Ona, we use these principles to design data management systems for purposes as varied as national immunization campaigns, M&E for tree planting efforts, cash distribution programs, and ed-tech interventions.
Each system is different in the business logic and program objectives, but all require a data stack capable of integrating information from different sources and creating a set of metrics that are well understood by the program stakeholders.
Key learnings we have seen for our clients from the switch in tooling include:
1. Simplify data ingestion.
Development projects rely on many data collection sources using systems that are less standard in the business world, such as DHIS2, Primero, RapidPro, ODK, CommCare, or custom applications. ELT-specific software can help create and maintain connectors to such sources. This is something that information system players like OpenFN and Ona have invested in a library of connectors for these tools that can be used to quickly support integrations.
2. Transformation layer combines data.
Many M&E activities require merging data from different sources, for example when collecting a campaign data using ODK and comparing progress against targets in a planning spreadsheet. Using a tool like DBT, the merging logic is written in code: data from raw tables is combined into transformed tables that are used for reporting, bringing three main advantages.
- First, the data transformation steps can be tested and versioned following software engineering best-practices, leading to a more rigorous and maintainable process.
- Second, the data can be processed closer to real time, meaning that dashboards and reports can be updated automatically without manual work once the system is set up.
- Third, as reporting needs evolve, creating new transformations or indicators does not require any changes to the data connectors: the connectors are generic and reusable while the transformations are project-specific.
3. Design for modularity and flexibility.
Because tools in a modern data stack are easy to integrate but independent from one another, it is also possible to swap similar components over time to meet new needs. If a new data ingestion technology or BI tool becomes more relevant for a project, an organization can use the new tool while maintaining all other elements of the stack.
Given the limits of budgets and tech skills in many development organizations, being smart and flexible with tool selection can allow entities to better manage their IT spend and occasionally invest in new tooling that will be more accessible to staff in the field and/or to donors.
Thinking about data as a stack and embracing new technologies can seem daunting, but organizations willing to adopt these best practices will benefit greatly. Tools for ETL and data transformations are mature enough for the development sector, enabling an easier relationship with data in their M&E activities and beyond.
Knowing about the trends is the first step to take action, but some expert help can also be useful to understand the needs specific to any organization and how to manage an infrastructure with several technology layers. Building on our experience, Ona has a dedicated service to help organizations manage their data by setting up and hosting a modern data stack. We call it Canopy.
The post 3 Advantages of a Modern Data Stack for Digital Development appeared first on ICTworks.