Using FHIR with Google Cloud, BigQuery, and the AI Platform
From our XLSForm definitions in Ona Data to our JSON Forms in OpenSRP, the work we do at Ona is built upon community driven standards. As we further integrate HL7 FHIR (Fast Health Interoperability Resources) into OpenSRP, we’ve been exploring the existing tooling available. In this post we’ll dive into the Google Cloud Platform (GCP) Healthcare offering and run through an example where we:
- Generate representative patient data in the STU3 FHIR format,
- Load that patient data into a FHIR store,
- Observe data in the FHIR store using BigQuery,
- Visualize and analyze those queries in the AI Platform.
- Export charts and machine learning models.
Our GLOVE approach to healthcare analytics transfers to other platforms and toolsets as the situation requires, including on-premise hardware. GCP lets us quickly set up a workflow to prototype new ways of exploring healthcare data. OpenSRP lets us ensure that, whether gathered at a household or in a facility, the data we are collecting has a well defined and FHIR compatible data structure.
Demo requirements
To follow along with the demonstration code below we will need the
- Google Cloud SDK, and a
- Google Cloud Platform account (the free trial will do).
We can use the link above to install the Google Cloud SDK and then run
gcloud beta healthcare
to install the Healthcare beta package.
Install and update Synthea
Synthea is a synthetic patient data generator program capable of generating health data for specific patient populations in various FHIR formats. Below we’ll clone the Synthea repository to our local machine and build it.
git clone https://github.com/synthetichealth/synthea.git
pushd synthea
./gradlew build check test
Enable the STU3 FHIR format, disable other FHIR formats
Here we adjust the Synthea configuration to generate data in the FHIR STU3 format. We can also use the DSTU2 format, but we must choose one or the other for this example.
vi src/main/resources/synthea.properties
Using the text editor of your choice, let’s open the synthea.properties file and adjust the content as below.
exporter.fhir.export = false
exporter.fhir_stu3.export = true
exporter.fhir_dstu2.export = false
exporter.hospital.fhir.export = false
exporter.hospital.fhir_stu3.export = true
exporter.hospital.fhir_dstu2.export = false
exporter.practitioner.fhir.export = false
exporter.practitioner.fhir_stu3.export = true
exporter.practitioner.fhir_dstu2.export = false
Generate health records in Synthea
Now that we have installed and configured Synthea, we will use its commands to generate data. The Synthea command line can generate location agnostic patient records, or alternatively accept a State and or City located in the United States, to generate location specific patient records. Below we pass a location and the -p option to generate ten patients representative of those seen in Eufaula, Alabama.
./run_synthea -p 10 Alabama Eufaula
Set our variables
Below we’ll set a number of variables that we refer to in the later commands run against the GCP SDK. Either create a new project or use an existing project, then read the ID and number from the project dashboard. In LOCATION make sure to choose a region that supports the services Healthcare, BigQuery, and AI Platform. Below is a breakdown of GCP feature support per region at the time of publication, January 2020.
| Healthcare | BigQuery | AI Platform | |
|---|---|---|---|
| asia-northeast1 | |||
| asia-southeast1 | |||
| europe-west2 | |||
| europe-west4 | |||
| northamerica-northeast1 | |||
| us-central1 | |||
| us-west2 |
These are the variables to set in the terminal for the remaining commands.
PROJECT_ID=[our project ID]
PROJECT_NUMBER=[our project number]
BUCKET=[a bucket in GCP]
FOLDER=[a folder in the above bucket, doesn't need to exist]
LOCATION=[a GCP region]
FHIR_STORE=fhirStore
DATASET_ID=fhirDataset
Feel free to adjust the names of the FHIR_STORE and DATASET_ID as desired.
Grant permissions
Here we grant permissions to the Cloud Healthcare Service Agent on the storage and BigQuery roles that it will need to access.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-healthcare.iam.gserviceaccount.com \
--role=roles/storage.admin
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-healthcare.iam.gserviceaccount.com \
--role=roles/bigquery.admin
Create healthcare dataset and FHIR store
First we create a healthcare dataset. The healthcare dataset exists in a specific region and can contain multiple different datastores of different formats within it. We can also use the online console to view, create, or modify healthcare datasets.
gcloud beta healthcare datasets create $DATASET_ID --location=$LOCATION
With the below command, we create a FHIR store within our healthcare dataset.
gcloud beta healthcare fhir-stores create $FHIR_STORE \
--dataset=$DATASET_ID --location=$LOCATION
Upload synthetic FHIR records to a bucket
Before we send our records into the FHIR store we have to push them to a bucket in cloud storage. The gsutil command below sends all the records we generated through Synthea to our cloud storage bucket.
gsutil -m cp output/fhir_stu3/* gs://$BUCKET/$FOLDER
Move records from a bucket into a FHIR store
Now that we have our records remotely available in a cloud storage bucket, we use the following command to transfer them from that bucket to our FHIR store.
gcloud beta healthcare fhir-stores import gcs $FHIR_STORE \
--dataset=$DATASET_ID \
--location=$LOCATION \
--gcs-uri="gs://$BUCKET/$FOLDER/**.json" \
--content-structure=BUNDLE_PRETTY
This command will block until complete and end by returning the number of successfully transferred records.
Create a BigQuery dataset
Here we create an empty dataset in BigQuery that we’ll later transfer our FHIR data to.
bq mk --location=$LOCATION --dataset $PROJECT_ID:$DATASET_ID
Export from a FHIR store to BigQuery
Now we’ll use the following command to transfer the FHIR records in our FHIR store into the new dataset we’ve created in BigQuery. This command will also block, but we can pass the --async option if we want to run it in the background.
gcloud beta healthcare fhir-stores export bq $FHIR_STORE \
--dataset=$DATASET_ID --location=$LOCATION \
--bq-dataset=bq://$PROJECT_ID.$DATASET_ID \
--schema-type=analytics
After transferring our data from our FHIR store to our BigQuery dataset, we can go to the BigQuery console to see the tables we created, preview the schemas and contents of the tables, as well as run SQL queries against the tables.
Explore BigQuery data with AI Platform Notebooks
For a more flexible, powerful, and persistent approach to exploring the BigQuery FHIR tables, we can use Notebooks in the AI Platform to make queries directly against our BigQuery datasets.
If we launch a Python 3 Jupyter Lab notebook, we can use the following code to run a query directly against BigQuery:
from google.cloud import bigquery
import pandas as pd
project_id = "[PROJECT ID]"
fhir_store = "[FHIR_STORE]"
client = bigquery.Client()
condition_age="""
SELECT code.coding[safe_offset(0)].display As Condition,
DATE_DIFF(CURRENT_DATE, PARSE_DATE('%Y-%m-%d', birthDate), YEAR) as Age
FROM `{project_id}.{fhir_store}.Condition` AS Condition
JOIN `{project_id}.{fhir_store}.Patient` AS Patient
ON Condition.subject.patientId=Patient.id
""".format(project_id=project_id, fhir_store=fhir_store)
In the above code, update project_id and fhir_store to match what we used in our command line variables. This query will join all the code.coding.display values from the Condition table with patient ages from the Patient table, as calculated using the birthDate values and the current date.
Notice that [safe_offset(0)] is required to handle the nested column names containing periods (.) that result from the manner in which BigQuery converts nested FHIR resources into table definitions. Using [safe_offset(0)] is also valuable when running SQL queries directly against BigQuery in the console.
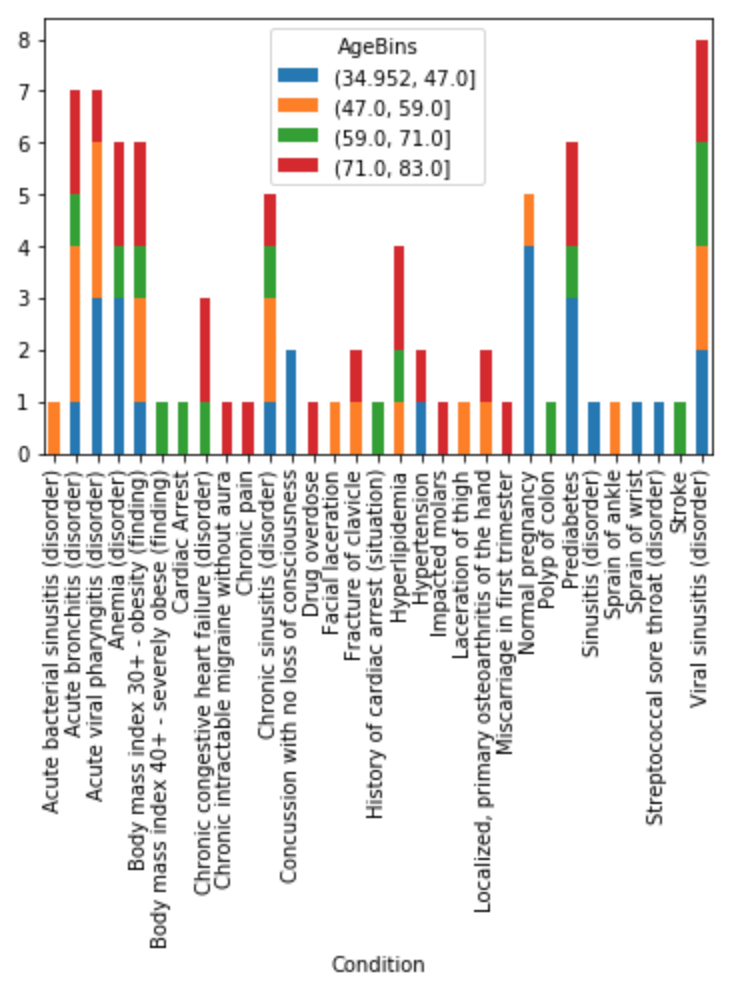
In the code below, we execute this query against our BigQuery client and convert the results into a Pandas dataframe. Then we take that dataframe and generate four age bins, equally split by frequency, from our Age column.
df = client.query(condition_age).to_dataframe()
df['AgeBins'] = pd.cut(df.Age, 4)
df.groupby(['Condition', 'AgeBins'])['Condition'].count().unstack('AgeBins').fillna(0).plot(
kind='bar', stacked=True)
Finally, we create a stacked bar chart with the conditions on the x-axis, the frequency on the y-axis, and the grouping colors representative of the age bins. The legend matches the colors to their age bin, where brackets (]) denote an inclusive interval and parentheses (() an exclusive interval.
With minimal effort we’ve described and scripted a repeatable process to generate data, transfer it into cloud storage, from there into a FHIR store, then into a scaleable database, and programmatically analyze it.
As more data becomes available in FHIR, we are excited to have tools like this to Generate, Load, Observe, Visualize, and Export it.