Applying the Principles for Digital Development to Data Platforms
In Streaming Ona Data with NiFi, Kafka, Druid, and Superset, we went into detail on our technical approach to building a streaming data architecture, yet we skipped over why this is important. Simply put, we think the widespread practice of building custom software solutions in international development is a waste of time and money. This isn’t a new idea. The Use Open Standards, Open Data, Open Source, and Open Innovation principle in the Principles for Digital Development is essentially a reaction to the scourge that is one-off software.
In addition to reducing duplicate work, our approach — implementing on top of open standards-based data platforms — will mean solutions that cost less and give builders more flexibility. These are essential features to successful ICT4D projects, which supports our raison d’être at Ona: to build technology solutions that improve people’s lives.
In the context of health systems, our streaming data architecture means we can already create a single pipeline that receives information from an electronic medical record system, enhances it with demographic data, and then visualizes indicators on a website, all without building custom software. This is what it looks like:
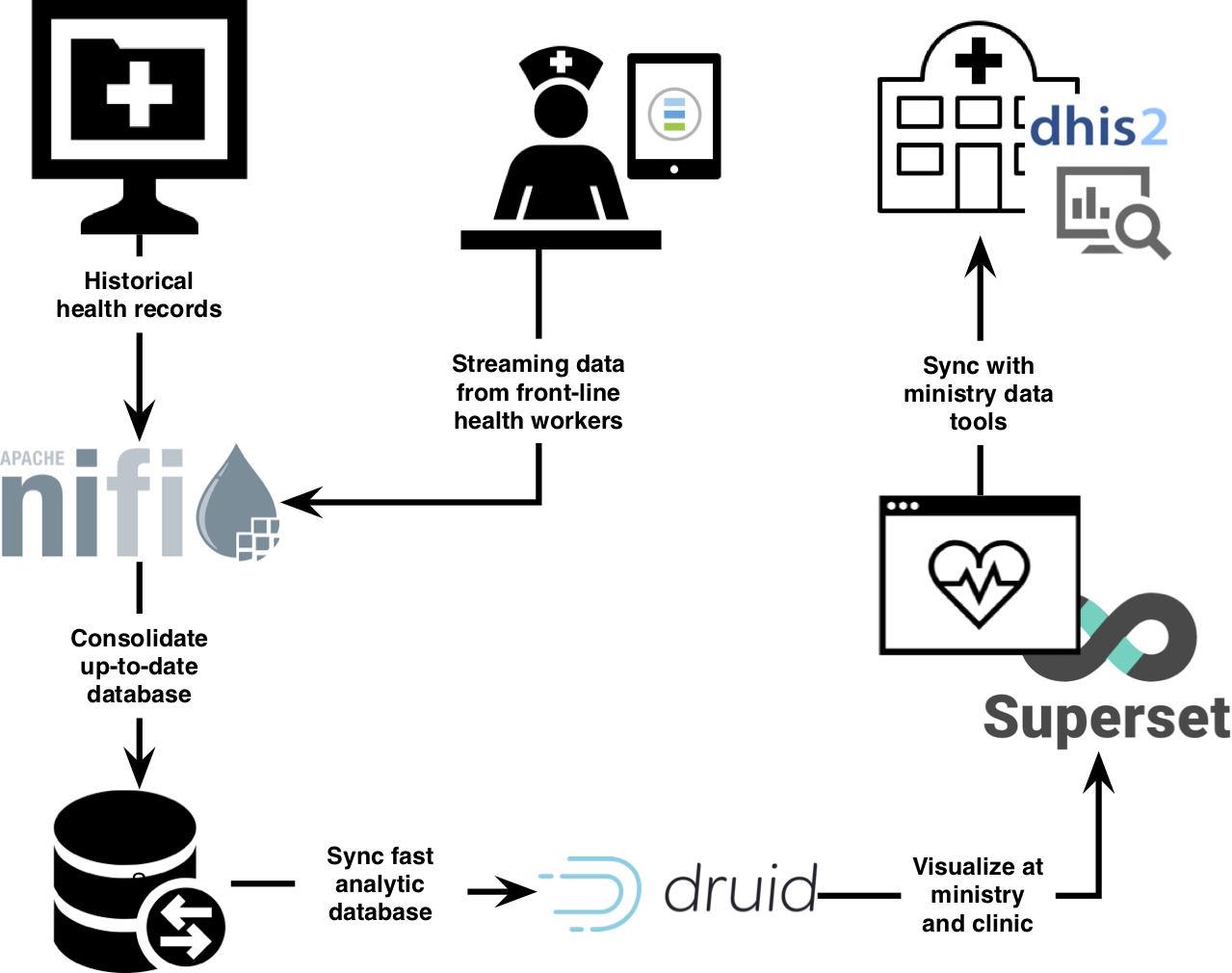
Using industry-standard data platforms lets us reconfigure and reuse the same system for different health use-cases or for any particular needs a client with data might have. We can also extend this system by adding machine learning tools and connecting them to existing platforms, products and data. Most importantly, our clients can access the visualization and data ingestion platform themselves. They can play with the charts and data pipelines to discover uses we would have never imagined.
Are custom data integration tools really a bad investment?
Yes, they are. Many web applications, especially in ICT4D, solve the same problem of fusing multiple data sources and visualizing them. Everyone is interested in outputs: eye-catching and informative visualizations, which motivate collecting inputs: raw data. However, in between there is a mess of intermediate analytics and custom data engineering work.
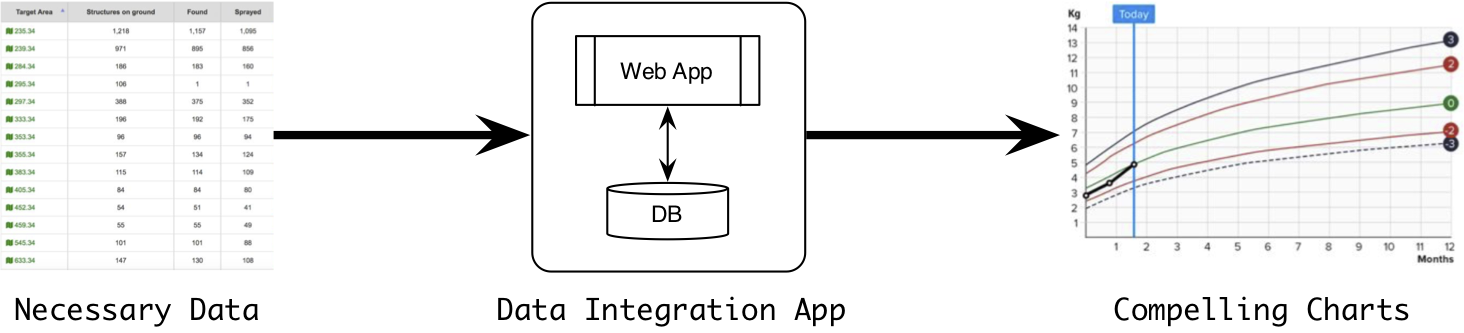
The easiest way to handle the messy intermediate work is to create a custom solution, i.e. a transactional database combined with a common web framework. This seems like a reasonable solution that fulfills project requirements. How harmful could it be?
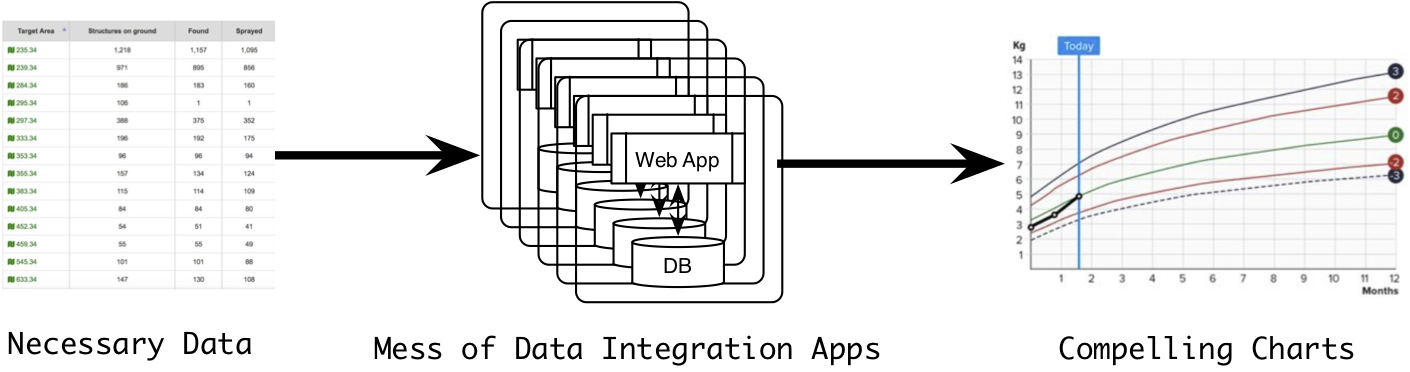
Quite harmful, unfortunately. For unique problems that only need to be solved once, this solution makes sense. However, data integration problems are not unique. Common problems such as connecting to other systems (e.g. DHIS2 or OpenMRS), adjusting or cleaning raw data, and fine-tuning charts and other visualizations need to be solved in most projects. We end up rebuilding the same thing over and over. Worse still, custom solutions become unmaintained, dated and eventually discarded after funding ceases.
As builders, we see these patterns but do not have the time or the budget to do anything about it. Instead, we write good code — extensible with common standards and thorough testing — but this narrow-minded focus on technical excellence lets us overlook that we have spent more resources building out a series of separate web applications than we would have if we had invested in a long term solution.
Open source data tools are the answer
What are our options? Going back to combine these separate applications into a single platform is untenable, because we will be forced to accommodate design decisions made for those single applications. We started looking for an answer by looking at our previous work. Every tool we’ve built breaks down into three components:
- Aggregation
- Merging
- Analytics and Visualization
Well-architected and well-maintained open source solutions exist for each of these components. Among others, Elastic, NiFi, and Kafka can solve the aggregation problem. Storm, Flink, Spark, and Apex can solve the merging problem. Hadoop, Druid, Pentaho, Pig, and Hive can solve the analytics problem. And Zeppelin, Superset, and ReDash can solve the visualization problem.
Open source data tools aren’t enough
Although these tools exist, they are hard to use. First, they are not packaged in an easy to use way, sometimes purposefully. Second, they are built to solve harder technical problems and scale rarely encountered in ICT4D to date. They are built to operate with high availability, high scalability, high throughput, and low latency — making them challenging to set up and operate.
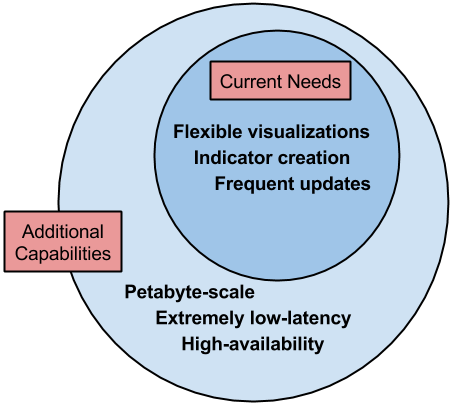
So our new problem is: how can we make the awesome but complicated existing tools easier to use? Enter the Enterprise Data Warehouse (EDW), the modular, open source tool we’re building to make integrating existing data tools simple. The EDW will fill a huge need in the ICT4D open source community and let us build better solutions faster while being adaptable to the changing needs of our partners.
Side note: building an EDW is a significant challenge (read: big investment) — so much so it is the competitive advantage of a number of companies.
These tools are common elsewhere, they should be in ICT4D
We see building an EDW as a disruptive change for ICT4D. A well-tested industry standard software package will make it easy for groups to solve data problems they’re facing today. At the same time, a EDW means faster integration with promising new technologies like artificial intelligence, comprehensive data security, and internet of things. To accelerate this shift in the industry, Ona has released open source Ansible roles to automatically set up and configure data warehouse components.
Additionally, we offer our partners an EDW solution that addresses the unique needs of the ICT4D space, including data sovereignty, aggregating data across heterogeneous data sources, mixed deployments that are both in the cloud and on-premise, limited hardware resources, and limited or unstable network connectivity. Program monitoring based on real-time data is an important part of all the projects we are involved in, and will become essential to any project’s success in the increasingly network-connected future (e.g. Internet of Things). Building these tools the correct way, by custom building as little as possible, is the most cost-effective and — we believe — the best approach.
The EDW prepares us for what’s next
An ecosystem of mature tools covering all the use-cases we outlined above has only become available in the past year or so. Two recent changes, first that these tools are mature and available, second that successful projects require real-time feedback and expect to be used at scale, have shifted the balance and justify a more thoughtful approach to data systems tooling. An EDW built from open source components is the perfect solution for this job. It future-proofs our tools and our partners’ projects. We can operate efficiently from village-scale to planet-scale, and when we need to incorporate new technologies, it’s as close to plug-and-play as possible.
For example, a global organization that’s in the process of deploying what they expect to grow into a planet-scale SMS-reporting tool will eventually have datasets in the high terabytes and then petabytes. To handle a rapidly growing dataset of this size, process it in real-time, and accomplish its mission effectively this organization will need to use an EDW that can accommodate this growth and at the same time is capable of handling its current smaller-scale needs at a reasonable cost.
If you are interested in exploring how an EDW could help address your needs please contact us at sales@ona.io
We’d like to acknowledge the World Health Organization, Johns Hopkins University, VillageReach, the Bill and Melinda Gates Foundation, and Johnson & Johnson for supporting us in this work.